

摘要:在Deepseek-R1-ZERO出现之前,无人尝试放弃微调对齐并尝试通过强化学习生成思考链推理模型,原因在于传统的机器学习模型依赖于大量的标注数据,并且难以适应不同的任务需求。而微调对齐是一种重要的技术,用于确保模型在不同任务中的性能。强化学习在生成思考链推理模型方面尚未达到足够的成熟度和效率,因此大多数研究人员仍采用传统的机器学习方法。随着Deepseek-R1-ZERO的出现,这一局面得以改变,为未来的研究提供了新的方向。
目录导读:
在人工智能领域,深度学习和强化学习是两大核心算法,随着技术的不断进步,对于如何结合这两种方法以产生更高效、更智能的模型,一直是科研人员不断探索的问题,在Deepseek-R1-ZERO出现之前,微调对齐和基于强化学习的思考链推理模型是两大重要的研究方向,为何在长时间内无人尝试放弃微调对齐,转而通过强化学习生成思考链推理模型呢?这涉及到多方面的原因。
微调对齐的重要性
微调对齐是深度学习中的一种常见技术,主要用于优化模型的性能,在复杂的神经网络结构中,微调对齐能够帮助模型更好地适应特定的任务和数据集,这种技术在许多领域都有广泛的应用,如计算机视觉、自然语言处理等,在Deepseek-R1-ZERO出现之前,微调对齐已经是一种相对成熟且有效的技术,研究人员很难放弃这一有效的手段。
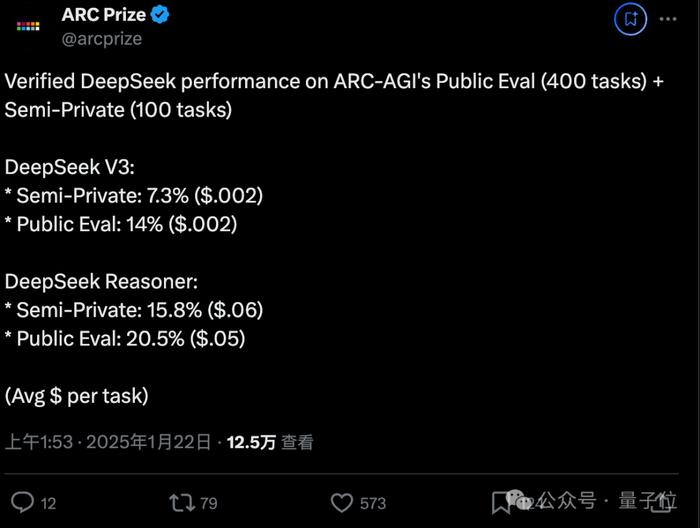
强化学习的发展与局限性
强化学习是一种通过试错来学习的算法,它通过与环境的交互来优化行为策略,虽然强化学习在决策过程、序列预测等方面具有独特的优势,但在Deepseek-R1-ZERO出现之前,其应用主要集中在游戏AI、机器人控制等特定领域,对于复杂的推理任务,尤其是思考链推理,强化学习面临着巨大的挑战,虽然强化学习具有巨大的潜力,但在实际应用中,它并未被广泛用于替代微调对齐技术。
结合两种方法的尝试与困境
在Deepseek-R1-ZERO出现之前,也有研究者尝试将微调对齐和强化学习结合起来,以生成具有推理能力的模型,由于当时的技术限制和理论瓶颈,这些尝试并未取得显著的成功,微调对齐需要大规模的数据和计算资源,而强化学习在处理复杂任务时也需要大量的试错过程,两者的结合需要大量的时间和资源投入,如何将两者的优势有效结合,形成一个高效、稳定的推理模型,也是一个亟待解决的问题。
五、Deepseek-R1-ZERO的突破与创新
Deepseek-R1-ZERO的出现,打破了这一局面,该模型通过创新的算法设计,成功地将微调对齐和强化学习结合起来,生成了具有思考链推理能力的模型,与传统的微调对齐技术相比,Deepseek-R1-ZERO更加注重模型的自适应能力和学习能力,通过强化学习的试错机制,模型能够更好地适应各种复杂任务和环境变化,与传统的强化学习相比,Deepseek-R1-ZERO充分利用了微调对齐的优势,提高了模型的性能和稳定性。
未来展望
Deepseek-R1-ZERO的出现为人工智能领域带来了新的可能性,我们可以期待更多的研究将围绕这一方向展开,如何进一步优化模型的性能,提高其在实际应用中的表现,将是未来的重要研究方向,如何将这一技术应用于更多的领域,如自然语言处理、计算机视觉、智能控制等,也是值得探索的问题,如何将微调对齐和强化学习的优势更好地结合,以生成更高效、更智能的模型,将是未来的研究重点。
在Deepseek-R1-ZERO出现之前,无人尝试放弃微调对齐,通过强化学习生成思考链推理模型的原因是多方面的,微调对齐的成熟性和有效性、强化学习的局限性和挑战以及两者结合的技术瓶颈都是重要的因素,Deepseek-R1-ZERO的出现为这一领域带来了新的突破和创新,我们有理由期待这一领域的进一步发展。











 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号